Advanced Prompt Engineering: Prefix Tuning - 12/01/2024
In the world of AI, prompt engineering is changing the game for Language Models (LLMs).
Advanced Prompt Engineering: Prefix Tuning
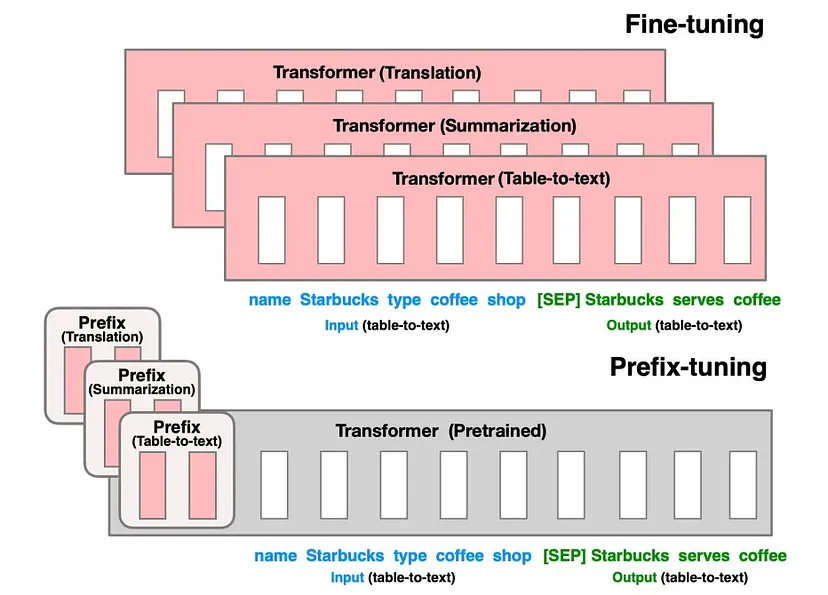 Source: https://aclanthology.org/2021.acl-long.353.pdf
Source: https://aclanthology.org/2021.acl-long.353.pdf
Introduction
In the world of AI, prompt engineering is changing the game for Language Models (LLMs). Thanks to the simplicity of Zero-Shot Learning, anyone, regardless of technical expertise, can now create custom prompts for better and personalized results. The cool thing about prompt engineering is that it lets you get useful info from a model, even if it wasn’t trained for a specific job. This shift means that each well-thought-out prompt becomes a key to unlocking the full potential of language models, reshaping how we interact with AI in the future.
Yet, there are some drawbacks to this approach. Crafting the perfect prompt often demands numerous adjustments to yield optimal results, presenting a slight challenge. In fact, it can be a bit tricky for individuals who may resort to experimenting with random prompts. Surprisingly, this trial-and-error method sometimes leads to unexpected outputs, unlocking possibilities that were initially unknown. Also, not all LLMs can perform multiple downstream tasks using only prompts.
Fine Tuning vs. Prefix Tuning
In the past, we relied on transfer learning to easily fine-tune models for new tasks. However, with today’s Language Models (LLMs) boasting millions, if not billions, of parameters, the process of fine-tuning has become resource intensive. This poses a challenge, especially for everyday researchers who might not have access to the substantial resources required for fine-tuning a Large Language Model.
Prefix tuning is a technique aiming to streamline the process. Instead of relying on manual prompt engineering, it focuses on learning a continuous prompt that can be seamlessly optimized end-to-end. This learned prompt, when added to the model’s input, acts as a guiding beacon, providing the necessary context to steer the model’s behavior in alignment with the specific task at hand. It’s like giving the model a customized set of instructions without the hassle of intricate manual tweaking, making the entire process more efficient and dynamic. It also doesn’t require training multiple parameters from the model, training only less than 1000× the parameters of the model.
How Prefix Tuning works
Prefix Tuning essentially prepends a learned continuous vector, called the prefix, to the input of the pretrained model.
Let’s take an example. Imagine we are prefix-tuning a Large Language Model (LLM) for Hate Speech Classification. The model takes an input x tweet and generates an output y which is the classification “Hate” or “Non-Hate”.
In prefix tuning, we’re doing a simple yet clever move — mixing x and y into a single sequence, let’s call it z = [x; y]. Why? Well, this combo creates a kind of “encoder-like” function. It’s super handy for tasks where y depends on x. It’s called Conditional Generation. This way, the model can smoothly go back and forth between x and y using its self-attention skills.
Moving along in the process, we introduce a prefix vector, let’s call it u, which is placed at the beginning of our sequence z, resulting in the concatenated form [u; x; y].
The prefix vector u is a matrix with dimensions (prefix_length × d), where d denotes the hidden dimension size. To put it into perspective, consider a scenario with a prefix length of 10 and a hidden size of 1024. In this case, the prefix would house a total of 10,240 tunable parameters.
This unified sequence is then systematically input into the Transformer model in an autoregressive manner. The model engages in attentive computations, focusing on prior tokens within the sequence z to predict the subsequent token. Specifically, the model computes hi, representing the current hidden state, as a function of zi and the past activations within its left context. This approach ensures the Transformer’s ability to progressively anticipate the upcoming tokens in the sequence.
An annotated example of prefix-tuning using an autoregressive LM In the training phase, we fine-tune the prefix values to maximize the likelihood of generating the accurate output text y when provided with input x. The optimization process exclusively calculates gradients for the loss function concerning the prefix parameters. It’s worth noting that the parameters of the pretrained model remain entirely unaltered, maintaining their fixed state throughout this training iteration. This strategic separation allows us to refine the specific elements responsible for prefix tuning without disturbing the foundational pretrained model.
The prefix tuning methodology, as demonstrated in the research paper, achieves a performance level comparable to full fine-tuning on the E2E dataset, utilizing a mere 0.1% of the tuned parameters (250K compared to 345M). This highlights the remarkable efficiency of the approach. The prefix acts as a nimble adaptation mechanism for the pretrained model, offering a lightweight solution that significantly reduces the computational overhead while preserving substantial performance gains and injecting task-specific knowledge into the model.
Advantages of Prefix Tuning
Memory Efficiency: Prefix tuning stands out for its memory-efficient approach. Rather than storing a full copy of the pretrained model for each task, only a small prefix needs to be retained. This not only conserves storage but also facilitates scaling to handle a multitude of tasks efficiently.
Faster Training: The process of updating only the prefix parameters significantly accelerates training compared to full model fine-tuning. By avoiding gradient computation through the entire pretrained model, prefix tuning offers a substantial boost in training speed.
Modularity: One of the key strengths of prefix tuning lies in its modular design. The pretrained model remains fixed and untouched, eliminating the need for any modifications. This modularity allows for flexible combinations of prefixes and pretrained models, enhancing adaptability.
Better Generalization: Freezing the pretrained parameters enhances generalization to new datasets and topics. By relying on the inherent capabilities of the model rather than overfitting parameters, prefix tuning, as demonstrated in the research, exhibits superior extrapolation performance compared to full fine-tuning in certain scenarios.
Personalization: The independent learning of prefixes per user opens the door to personalized experiences. With a single pretrained model supporting personalized prefixes, it becomes a versatile tool for catering to individual user preferences.
Interpretability: The compact nature of prefixes enhances interpretability compared to large, fine-tuned models. This simplicity makes it easier to inspect and understand the specific knowledge injected into the model through the prefix, providing valuable insights.
Conclusion
In summary, prefix tuning offers an efficient, modular, and user-centric approach to steering large pretrained Language Models, presenting a compelling alternative to traditional full fine-tuning methods.